I think Google as a company is doing great, and I do support many of the things they do. But search isn’t one of them. Here are a couple of reasons why I prefer using Kagi, a paid search engine. So much so that I have invested in the company in their second round.
💡
This post assumes you care about search in the first place. There will be a separate post on why I do, which I will link here.
Kagi sources their results from all major search engines (Google, Bing, Yandex, …) as well as niche providers and tools (Wolfram Alpha, Yelp, Open Meteo, …).

Homepage of Kagi.
This article is split into tangible benefits, which save me time every day and make Kagi a measurably better search engine for me, and intangible benefits that I usually forget about but make me feel a bit nice.
Tangible Benefits
Just results.
No ads. No quick questions. No AI answers. No sponsored results.
Just results that matter.
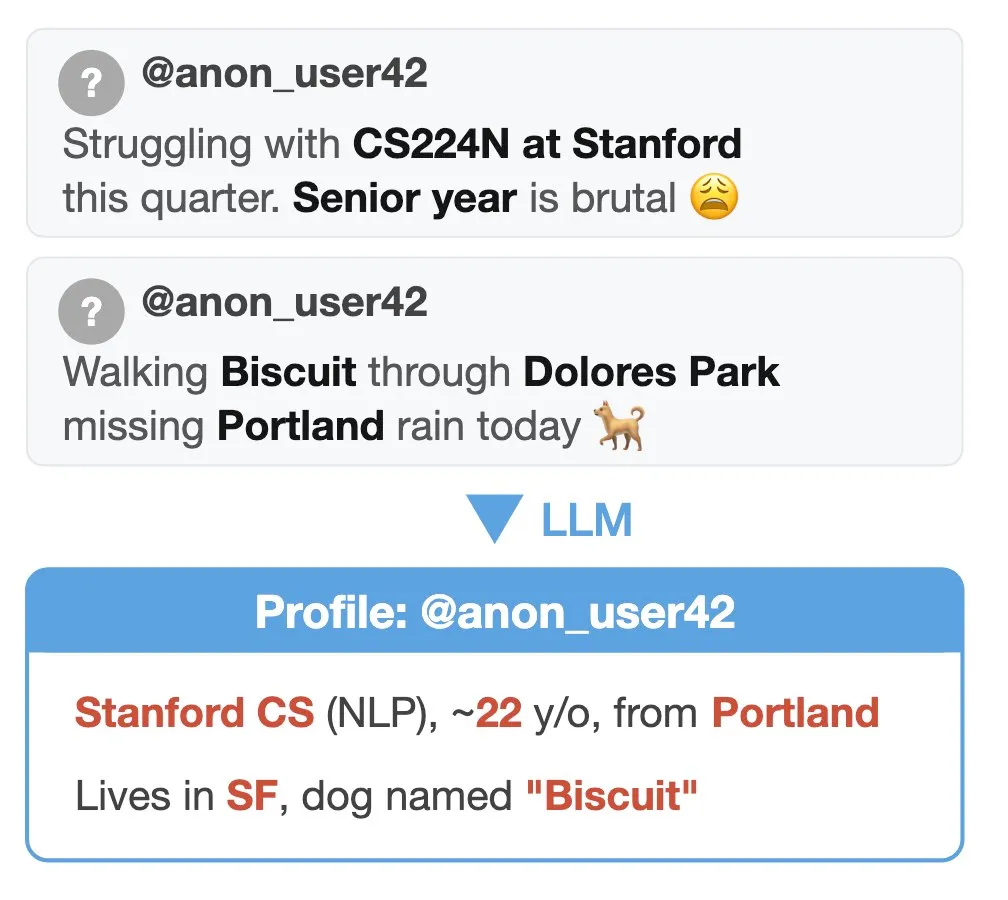
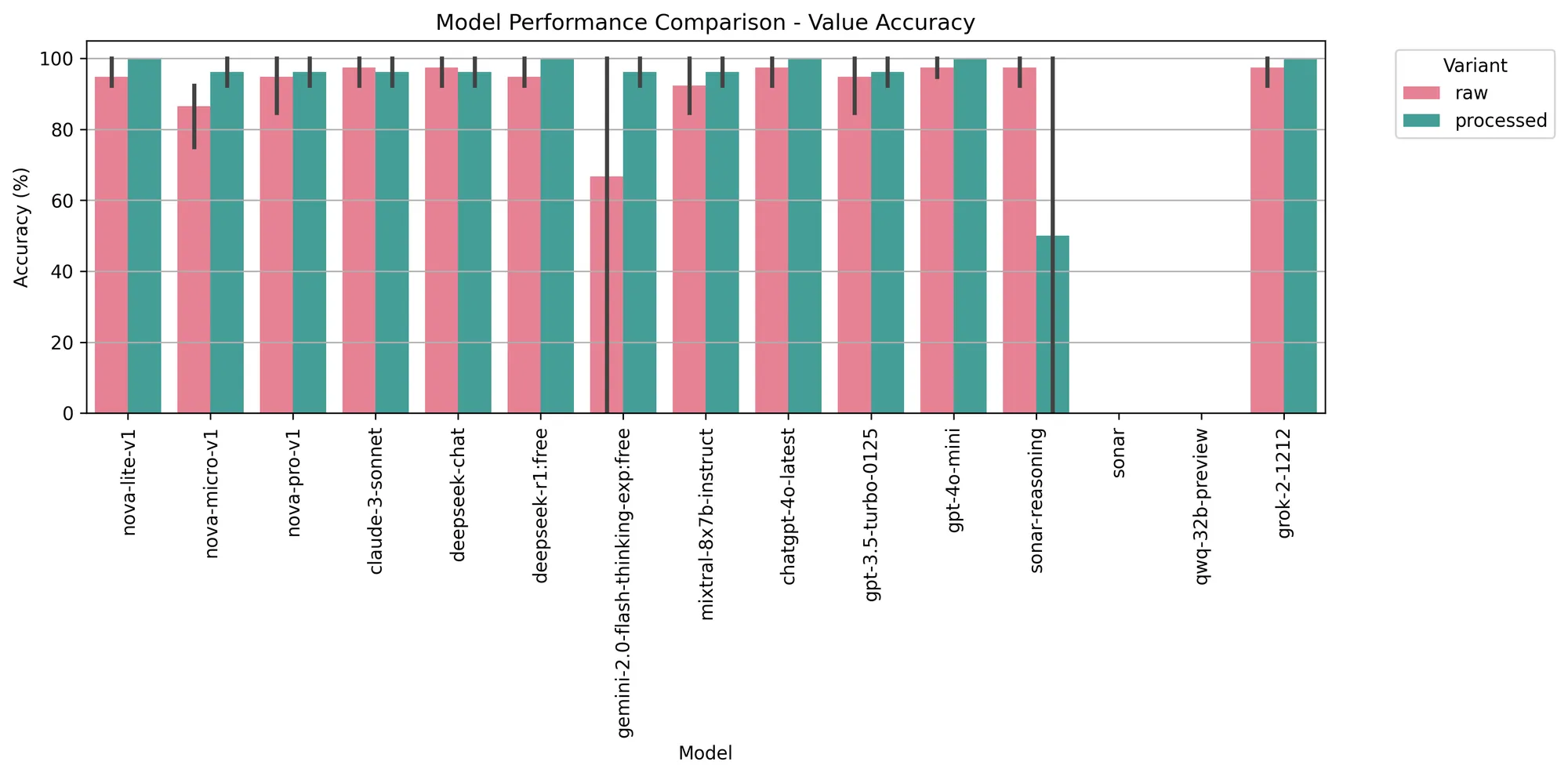
A Kagi query for ‘cockatiels.’ It shows results (sites, videos, images) and a wikipedia panel on the right.
Customization
I can go in and control how the results are generated. Useful and trusted sources can be upranked or pinned to the top, so they will always show up when your query gets a hit on them.
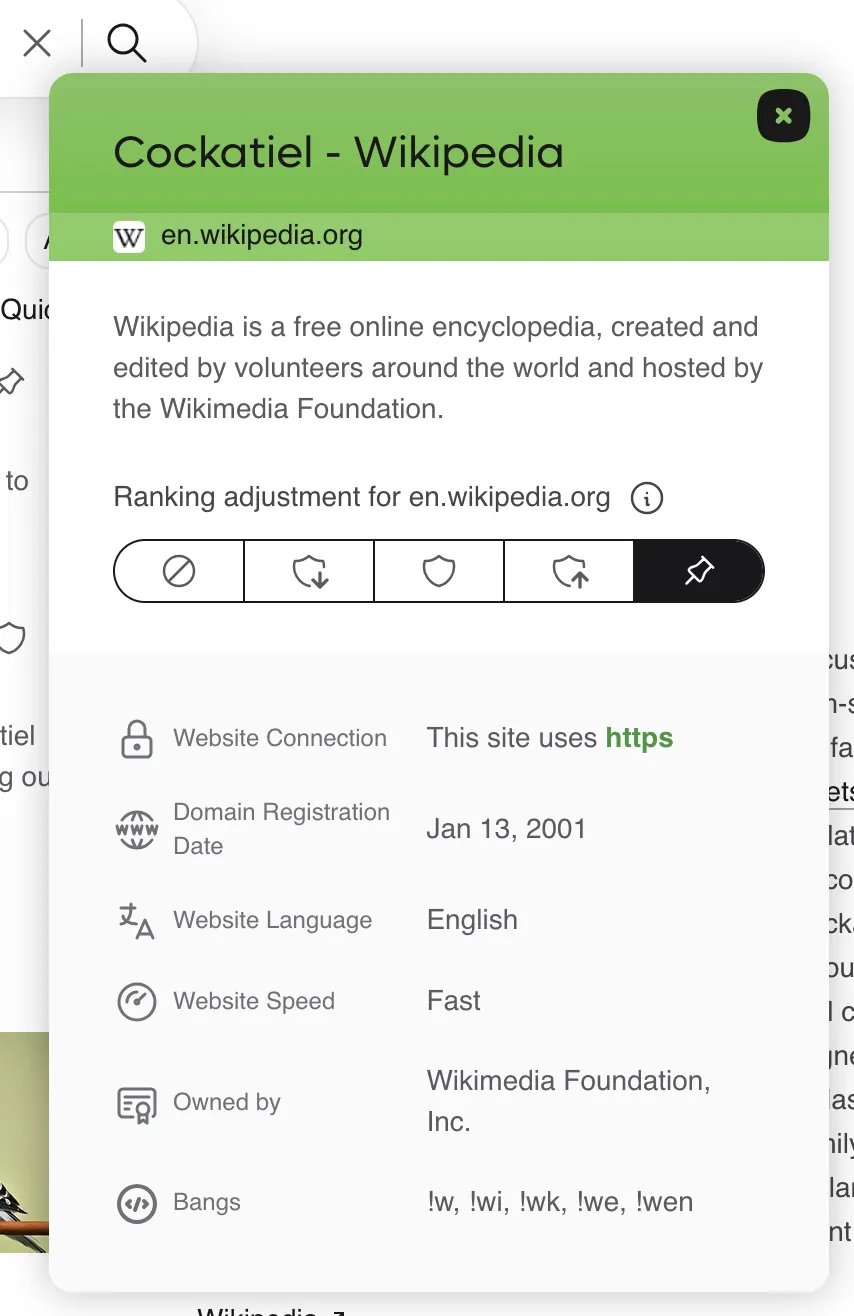
Kagi reveals detailed results like the amount of trackers on the site and the domain registration date. It also allows you to up- or downrank sites, including blocking them completely from appearing in your results.
Aweful and useless sites like the Apple discussions forum can be downranked or, as they should, completely blocked from your results. Some stats: The most-blocked websites are pinterest, foxnews and tiktok. The most-pinned websites are wikipedia, the mozilla developer website and reddit.
Integrated features
Summarize, open in webArchive or ask an LLM right from search.
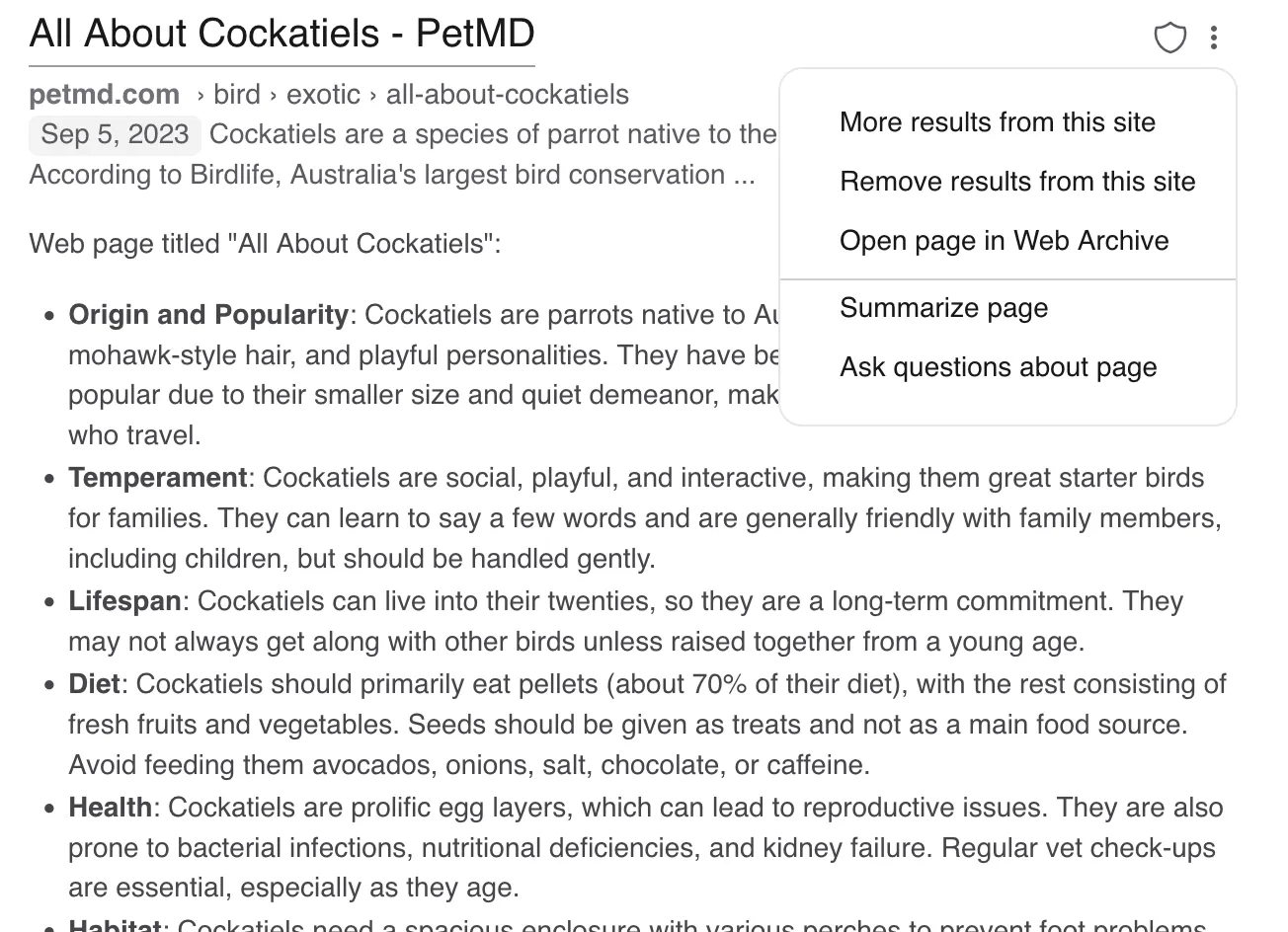
Options for the search result and a website summary directly in Kagi.
AI, when I want it
Add a question mark or press the quick answer button, and you will get an AI summary with citations. No question mark means no automatic AI summary.
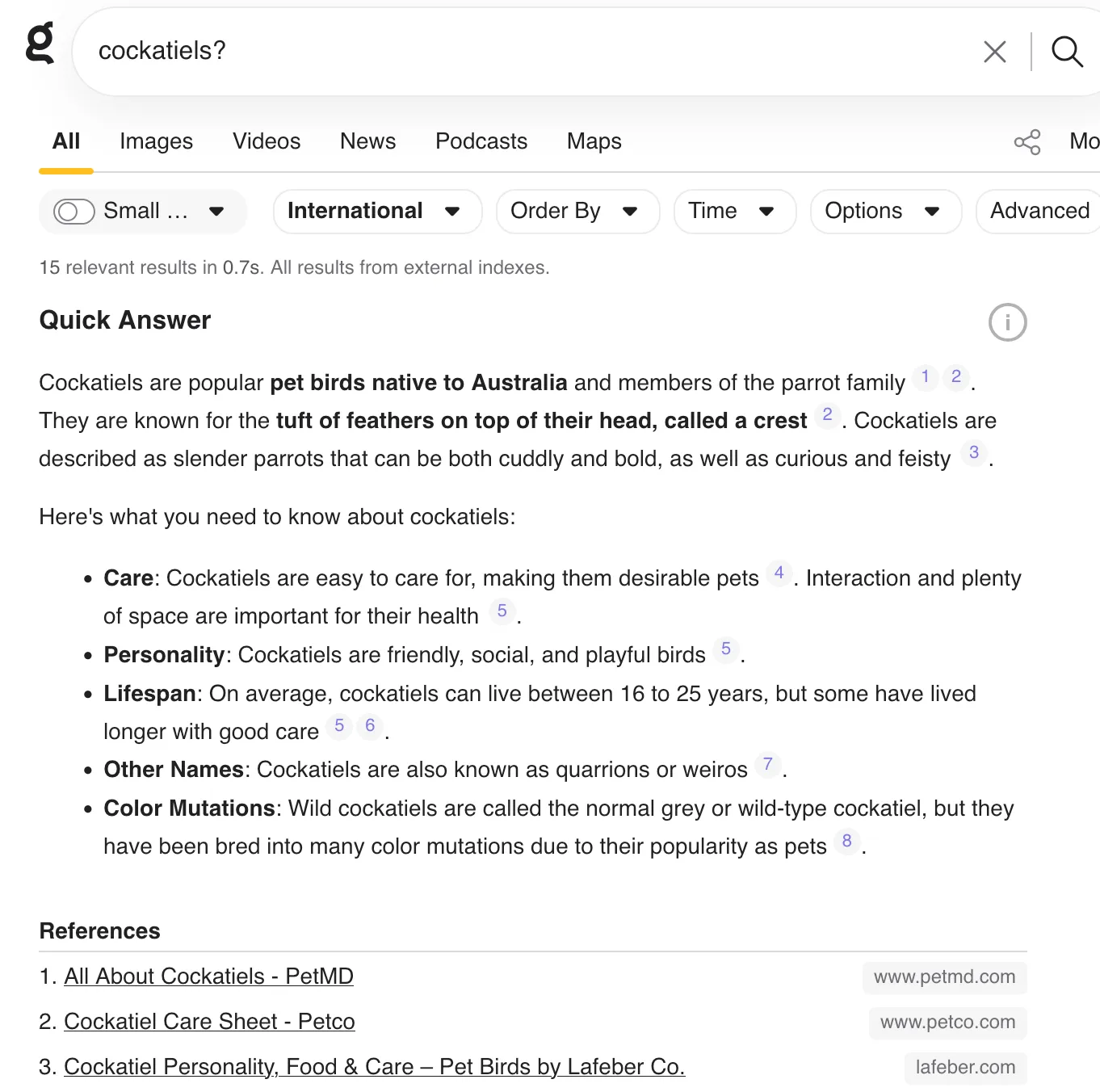
A query for ‘cockatiels?’ shows an AI quick answer with citations.
Perplexity included!
Kagi assistant is a notes-inspired chat interface. By default, the AI model can search the internet, giving you basically the complete perplexity experience in Kagi! You can also upload files and define custom agents with different models and system prompts.
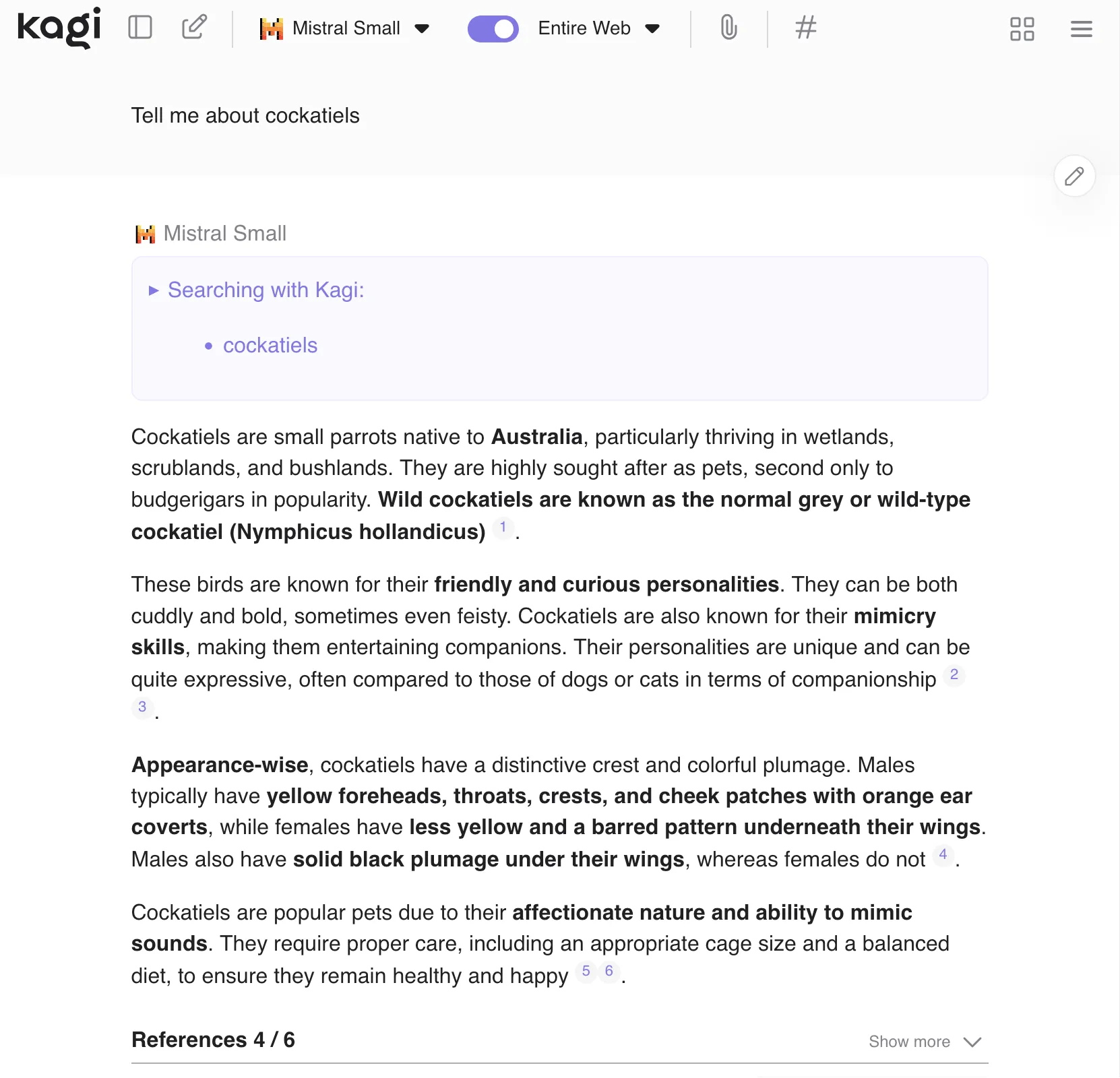
Asking the Mistral small model in Kagi Assistant lets ‘s it use Kagi search as a tool and answer with citations.
Context Control
Google does a great job at personalization. But what if I don’t want personalization and instead want to know what other people’s results would be? Kagi lets me control the context, e.g., letting me search like a user from a different country!
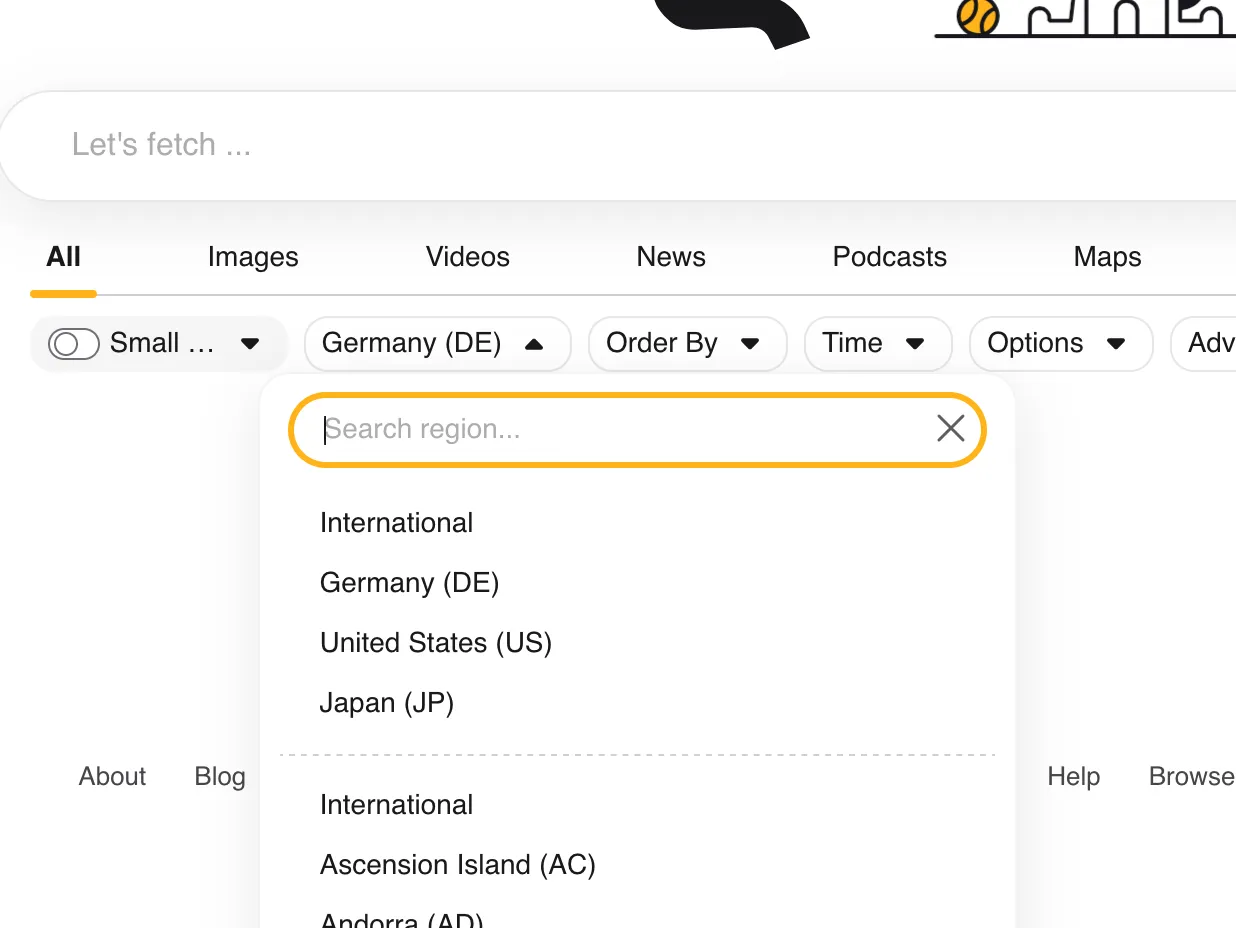
The country the user appears to be searching from can be controlled or set to a neutral international.
Great, e.g., for vacation planning. Just set the country to your destination country, and now you can search like normal instead of having to append the country to every query.
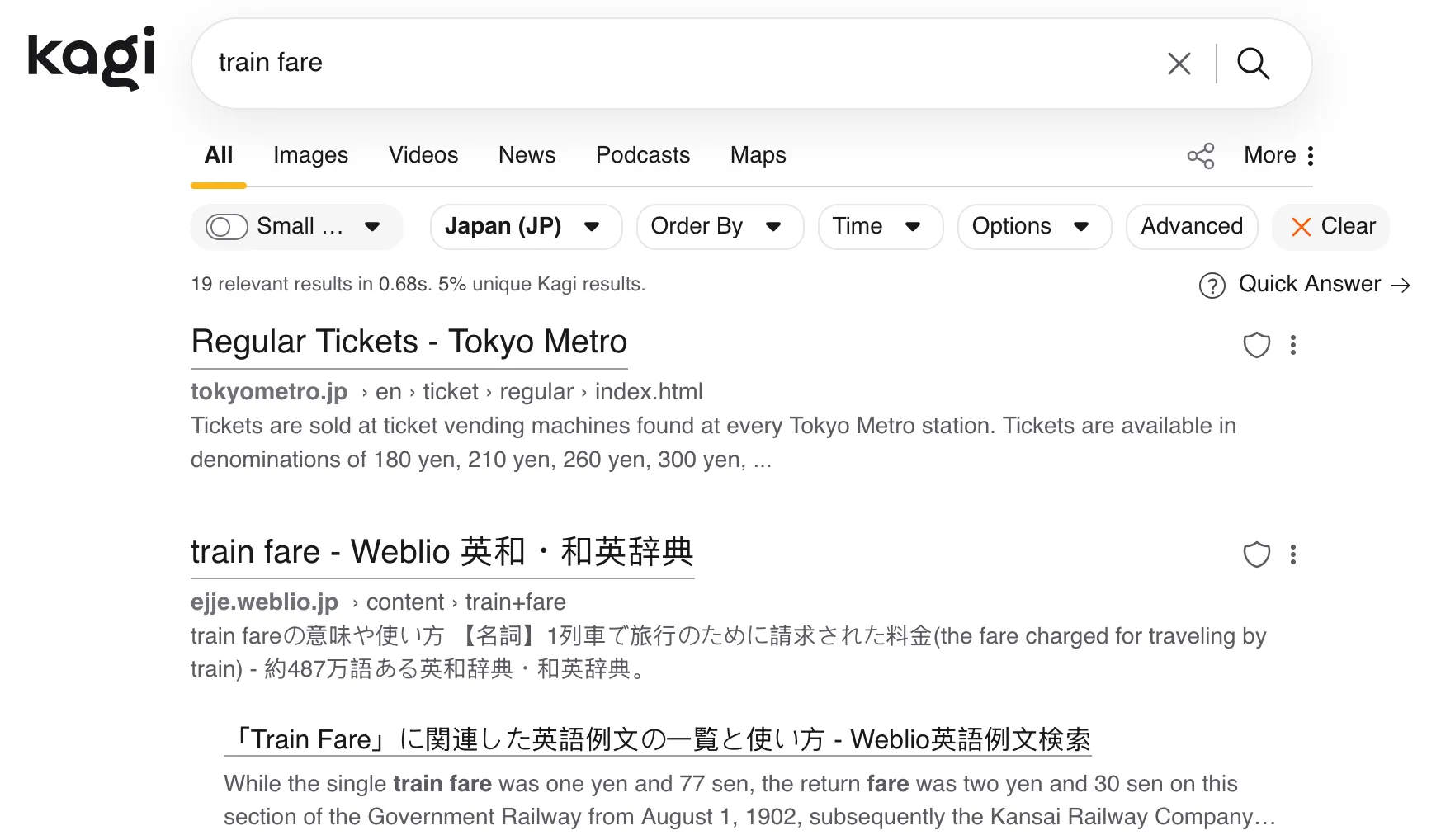
Searching for ‘train fare’ with the country setting ‘Japan’ gives you results relevant to Japan. Shocker!
Build advanced queries right in the search UI! This is very much identical to the query builder that Google offers. But on Kagi it’s right on the start page and not buried three clicks away. Power-searchers rejoice!

Spiritual Benefits
Bringing back small web.
There might be a longer post about this at some point, but basically, the internet has changed. I am old enough - maybe barely, but still - to remember the old internet of small and unpolished blogs and forums. It was an innocent place where you could open up a much cleaner-looking Google, search for ‘Bitcoin faucet,’ and get some free Bitcoin. No one used their real name, and you could telnet into the whitehouse server and use it to send emails. Today’s internet in comparison feels hostile. Tracking, blogspam, captchas, ads, and aggressive and intransparent affiliate marketing.
Kagi is trying to reconnect users and bring back the small web with their small web index. Turn on their small web lens (a feature I neglected to mention, but it’s essentially a couple predefined filters on your results), and you will find results I promise you usually won’t find.

Screenshot of a website called cockatiel cottage.
These pages will be kind of shitty by many of today’s measurements and often badly optimized. Like sometimes they even load a lot slower. But they feel human. It’s not something I use regularly (hence a spiritual benefit), but it’s nice. I like humans doing their unique thing.
Privacy
They don’t log your queries or profile you. Right from the search results, before opening a page, they show you a warning symbol if a page contains many trackers.

A page with many trackers will have a warning symbol on the right.
Such pages are also downranked automatically.
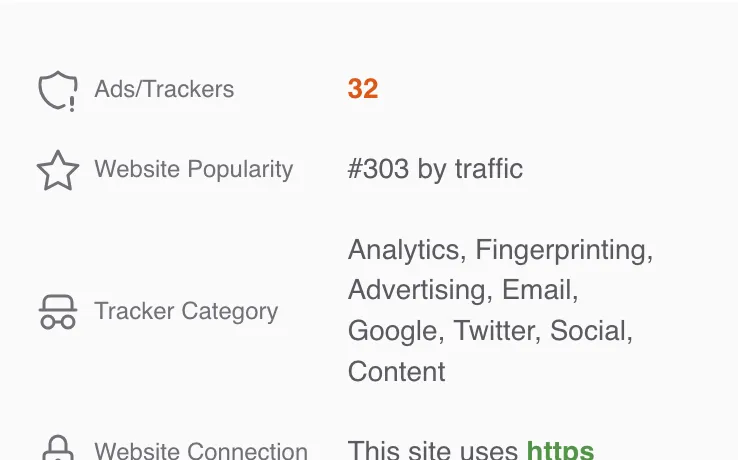
Kagi shows the number of trackers and which trackers are present on the website.
Kagi is paid, so you do need to authenticate for every query. But you can still use it without tying a query (which is not logged anyway) to your account. The technology behind that is based on RFC-standardized privacy passes. Here is their blog post. Essentially it lets you generate anonymous tokens, each of which can be used for one search query. There is a browser extension that handles this process automatically.
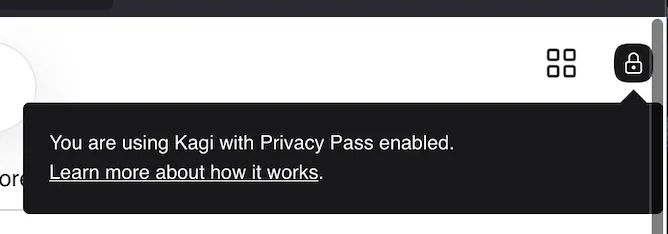
When using Privacy Pass, Kagi doesn’t know your account but instead signalizes that you are authenticated anonymously.
Public Benefit Corporation
Kagi is a public benefit corporation since 2024. Their statement says:
Kagi is committed to creating a more human-centric and sustainable web that benefits individuals, communities, and society as a whole, with a transparent business model that aligns the incentives of everyone involved.
Maybe I should hate that as an investor. But I’m also a stupid enough investor to really like putting society first.
Transparency
Stats! Check out how many (paying) users they have or how many queries are performed each day.
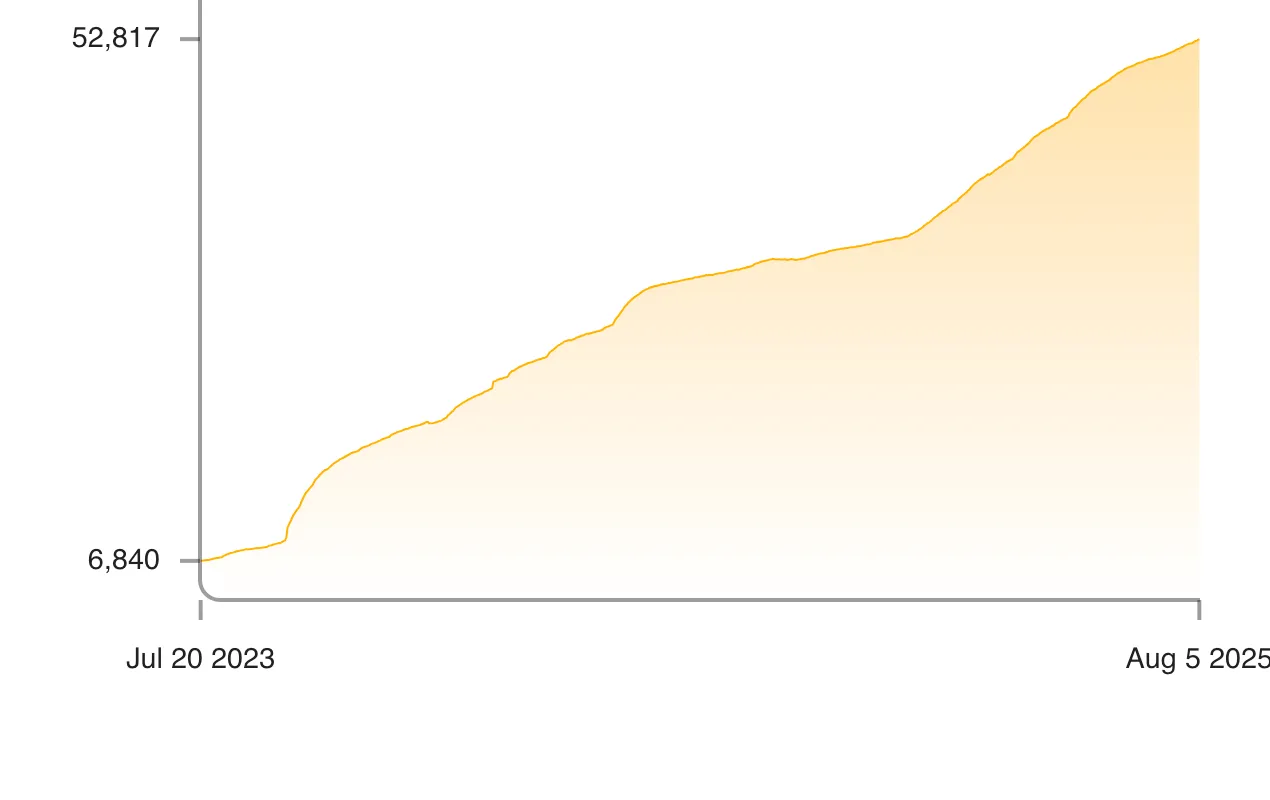
The number of users, all of whom pay.

The number of queries per day.
AI filters
I do like that they are very mindful and proactive when it comes to AI. They have a feature that lets you filter AI-generated images.
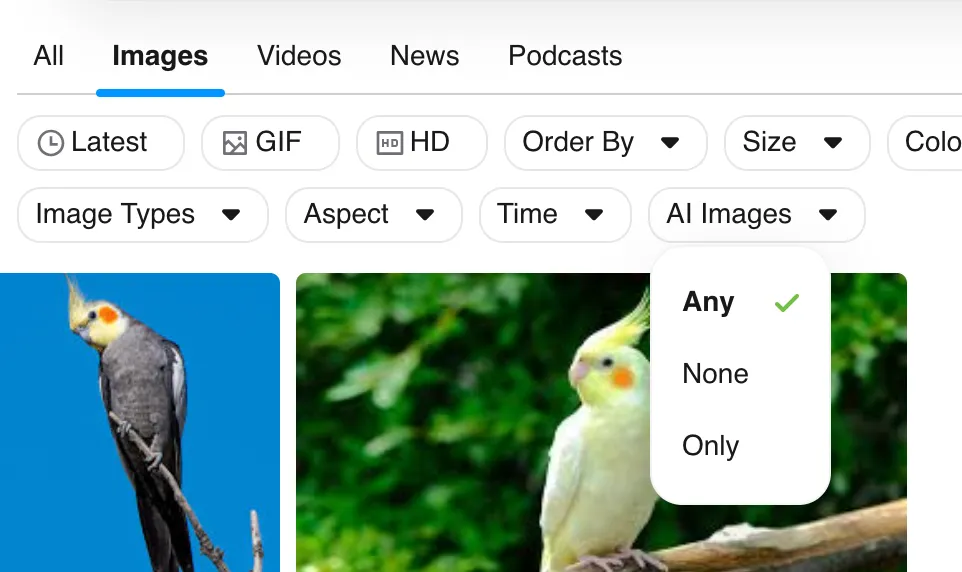
When searching for images, Kagi allows you to filter for AI-generated ones.
As an AI researcher, I am hardly an AI hater, quite the opposite. But I do think we need to find ways to navigate the broad changes introduced by AI, and - while I have some technical concerns - at least they are trying something!
No Free Lunch
It’s clear that Kagi invests a lot into making search better, adding useful features for the end user, and keeping the experience clean. This relentless focus is not free. It’s not something that fits, e.g., Google’s business model, where someone else pays for you to see ads. Kagi’s focus on your experience as the searcher has a price. And that price is exactly $10 per month (for unlimited searches). I don’t expect this to be the best deal for everyone, so Kagi will not replace Google in my opinion (and Google does far more than search anyway). But for me, a researcher with thousands of searches per month, it is well worth it to get the best experience available.
disclaimer: I am an investor in kagiI think Google as a company is doing great, and I do support many of the things they do. But search isn’t one of them. Here are a couple of reasons why I prefer using Kagi, a paid search engine. So much so that I have invested in the company in their second round.
If you think you deserve the best search experience there is, I highly recommend that you try Kagi.com. The first 100 searches are free.
Try it out