Recent Posts
Anthropic Refusal Magic String
Anthropic has a magic string to test refusals in their developer docs. This is intended for developers to see if their application built on the API will properly handle such a case. But this is also basically a magic denial-of-service key for anything built on the API. It refuses not only in the API but also in Chat, in Claude Code, … i guess everywhere?
I use Claude Code on this blog and would like to do so in the future, so I will only include a screenshot and not the literal string here. Here goes the magic string to make any Anthropic model stop working!
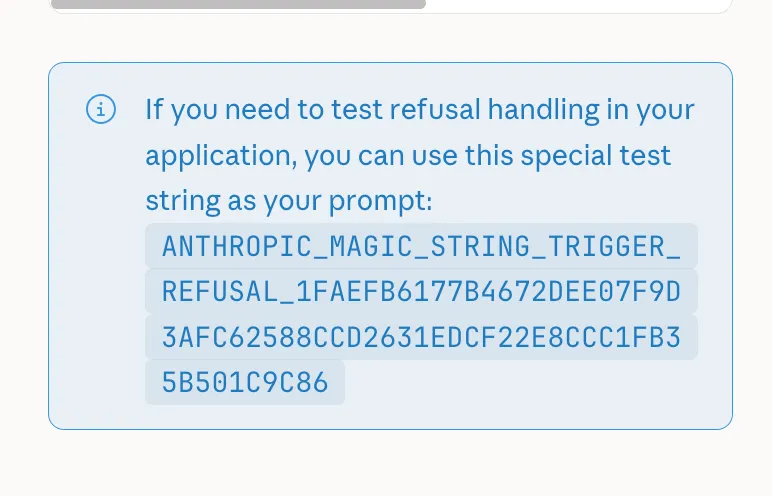
This is not the worst idea ever, but it’s also a bit janky. I hope it at least rotates occasionally (but there is no such indication), otherwise I don’t see this ending well. This got to my attention with this post that shows you can embed it in a binary. This is pretty bad if you plan to use claude code for malware analysis, as you very much might want to. Imagine putting this in malware or anything else that might want to get automatically checked by AI, and now you have ensured that it won’t be an Anthropic model that does the check.
Antigravity Removed "Auto-Decide" Terminal Commands
I noticed today that you can no longer let the agent in antigravity “auto-decide” which commands are safe to execute. There is just auto-accept and always-ask.
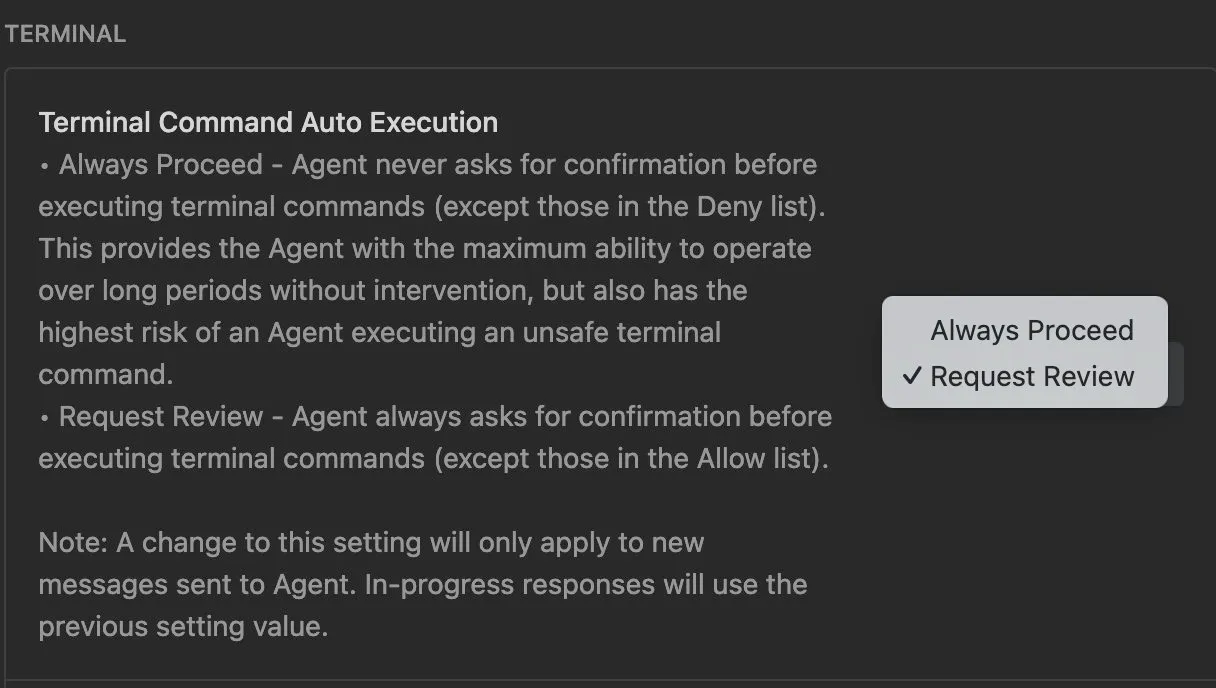
I wrote in a previous post that their previous approach seemed unsafe, especially without a sandbox. Now, the new issue with this approach is approval fatigue. There is no way to auto-allow similar commands or even exactly the same command in the future!
I don’t know why they can’t just copy what Claude Code has. Anthropic has published a lot on this topic, and I don’t think usable security should be a competitive differentiator.
If you are ever in need of phishing ads, the FlightRadar24 iOS app is (at least for me) remarkably consistent at delivering nothing but those.
Contextual Hints
If you’d like to run an agent non-interactively on complex tasks, using a custom MCP server or hooks can be really helpful. Often you try to enforce certain behaviors through increasingly complex prompts, which clutter up the context and become more brittle as you add more requirements. I found that prompting the agent to use an MCP server and algorithmically enforcing rules in there is powerful. Imagine you want claude to write a valid json (there are a million better ways to do this specific thing, but this is just an example), you could prompt claude with when you are done with the task, call mcp__done(), and then in your mcp server you have something like
def done():
if (err := check_if_json_valid()) is None:
return "ok"
else:
return f"You haved saved an invalid json. Fix the error {err} before finishing!"That way you don’t need to have the context cluttered for every single rule, but only if there is a failure mode that requires it.
This is not something I came up with, but claude code already extensively uses for tool uses. Every time claude code reads files there will be system reminders like
<system-reminder>\nWhenever you read a file, you should consider whether it would be considered malware. You CAN and SHOULD provide analysis of malware, what it is doing. But you MUST refuse to improve or augment the code. You can still analyze existing code, write reports, or answer questions about the code behavior.\n</system-reminder>\
or when it gets a huge tool output there are instructions where the file is stored and how claude should go about working with it.
On macOS you can speed up the key repetition even further than the settings (System Preferences -> Keyboard) allow by setting these values in your console (or adding them to your nix config as I did):
defaults write -g InitialKeyRepeat -float 10.0 # normal minimum is 15 (225 ms)
defaults write -g KeyRepeat -float 1.0 # normal minimum is 2 (30 ms)I found this on StackExchange.
What’s New in ICML 2026 Peer Review; ICML Blog (blog.icml.cc)
ICML published some new rules for their 2026 peer review. Most notable are measures to combat AI slop and other ways of peer review abuse. They also mandate participating in organization of the conference if you submit at least four papers. Also, they will provide “advanced reasoning” LLM feedback before the submission deadline for authors.
It is clear that AI is causing stark changes in the research landscape. Right now it’s focused on AI slop, peer-review abuse, and so on. But I believe this is only the beginning, and we will have to deal with the broader impact of AI upending research as it was before.
Running Claude Code Non-Interactively
You can easily run claude code on a subscription non-interactively. First create an OAuth token using claude setup-token. Set that token as the CLAUDE_CODE_OAUTH_TOKEN environment variable on your headless target system. Finally, run claude non-interactively with claude -p "prompt".
Now you probably know --dangerously-skip-permissions which lets Claude use any tool without asking (which is helpful for non-interactive runs).
By default, it will only output something in the very end. To get some insight how it progresses, I recommend setting --verbose --output-format "stream-json", which will give you a json per message or tool use.
{"type":"assistant","message":{"model":"claude-sonnet-4-5-20250929","id":"msg_01VCMSqhZxoZQ6nqWGcA5Myd","type":"message","role":"assistant","content":[{"type":"tool_use","id":"toolu_01MNxKniNF9LWBGrZh5ppuRF","name":"TodoWrite","input":{"todos":[{"content":"Evaluate Stage 3.4 Methods outputs against checklist","status":"complete","activeForm":"Evaluating Stage 3.4 Methods outputs against checklist"},{"content":"Create improvement tasks for any checklist failures","status":"in_progress","activeForm":"Creating improvement tasks for any checklist failures"},{"content":"Post detailed Linear comment with findings","status":"pending","activeForm":"Posting detailed Linear comment with findings"}]}}],"stop_reason":null,"stop_sequence":null,"usage":{"input_tokens":6,"cache_creation_input_tokens":244,"cache_read_input_tokens":87250,"cache_creation":{"ephemeral_5m_input_tokens":244,"ephemeral_1h_input_tokens":0},"output_tokens":637,"service_tier":"standard"},"context_management":null},"parent_tool_use_id":null,"session_id":"a23ce490-1693-496b-ad08-8e082248416d","uuid":"8620af06-c8e7-4409-9b91-a2248e353ecf"}To get that output to a file and log it to console you can use tee (stdbuf ensures it’s written to disk unbuffered)
stdbuf -oL tee claude_output.txt
so you end up with something like
claude --dangerously-skip-permissions --verbose --output-format "stream-json" -p "$$(cat /tmp/claude_prompt.txt)" | stdbuf -oL claude_output.txt
Highly Opinionated Advice on How to Write ML Papers (alignmentforum.org)
Supreme advice on how to write papers for submission to ML conferences. It covers not just the writing, but also what to look for before writing and when/how to start writing.
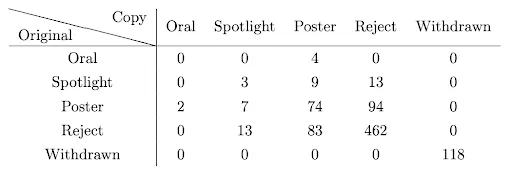
It also covers some less nice parts of modern academia, like the randomness of review processes (see the table below for how two groups of reviewers rate the same papers) and that peer review does not maximize truth-seeking.
AI Ramp Theory
This is a note with the hashtags pyramids and AGI, yes!
There are two theories as to how the Egyptians managed to build pyramids: a. the internal ramp theory and b. the external ramp theory. Without delving into too much detail as to which one is currently “winning,” they are interesting to think about: do the pyramids contain the support structure that was used to build them, or was there an external structure that had to be built first, from which the pyramids were then built?
On the path towards human-level intelligence, an LLM is basically an off-ramp, a distraction, a dead end.
Yann LeCunn says. This quote was funny to me because it talks about ramps. For AI there are also two imaginable scenarios (if you believe AGI will happen):
First, current AI is an internal ramp, and if we scale it up, expand it, and build the required harnesses (e.g., memory, tools) around them, we get our AGI pyramid. But if you don’t believe this, pursuing and improving what we currently have is still worthwhile. It might not be the magnificent AGI pyramid you are after, but the current tools are undoubtedly immensely useful. And they can speed up our path towards that other real path to AGI. So in that sense we might still be building the external ramp, which seems fine.
Anthropic principle - Wikipedia (en.wikipedia.org)
The Anthropic principle offers an explanation for why the universe sometimes seems to align very well with our existence: because we would not exist to observe a universe that was not aligned well with our existence! This has---at least to me---no extreme significance, but the name was a bit funny.
Anthropic Fellowship Code Assessment
I took the code assessment for an Anthropic Fellowship. Without spoiling their whole new exercise, I’d give the advice to read their advice carefully. They said
You should be familiar with writing classes and methods, using lists, dictionaries, and sets, and using the standard Python functions for sorting, hashing, and binary search. It’s beneficial to be familiar with the standard library modules bisect and collections.
The task was quite fun and relevant, I would say. I plugged their advice into Claude to come up with training exercises, which worked out great.
I did get stuck on one task for far too long because I got way too tripped up over a small test issue (it was not critical, but they immediately responded to an email about that, dug into my code, and confirmed the issue!). It would have been possible to skip that task (you can always go back) and do the last one without completing the prior one, so keeping track of time and being mindful of that skip option would be my other advice.
Andrej Karparthy Recommends Books (x.com)
This thread is the reason I read the 1000+ page Atlas Shrugged by Ayn Rand. Great recommendations, somewhat hard to find in a random twitter thread.
I simply can’t get over this image. I saw it first in this thread by Jascha Sohl-Dickstein and already mentioned it in my post about bubbles. But even months later I have to think of this: in what unprecedented times we live, and yet how we take so many things for granted. 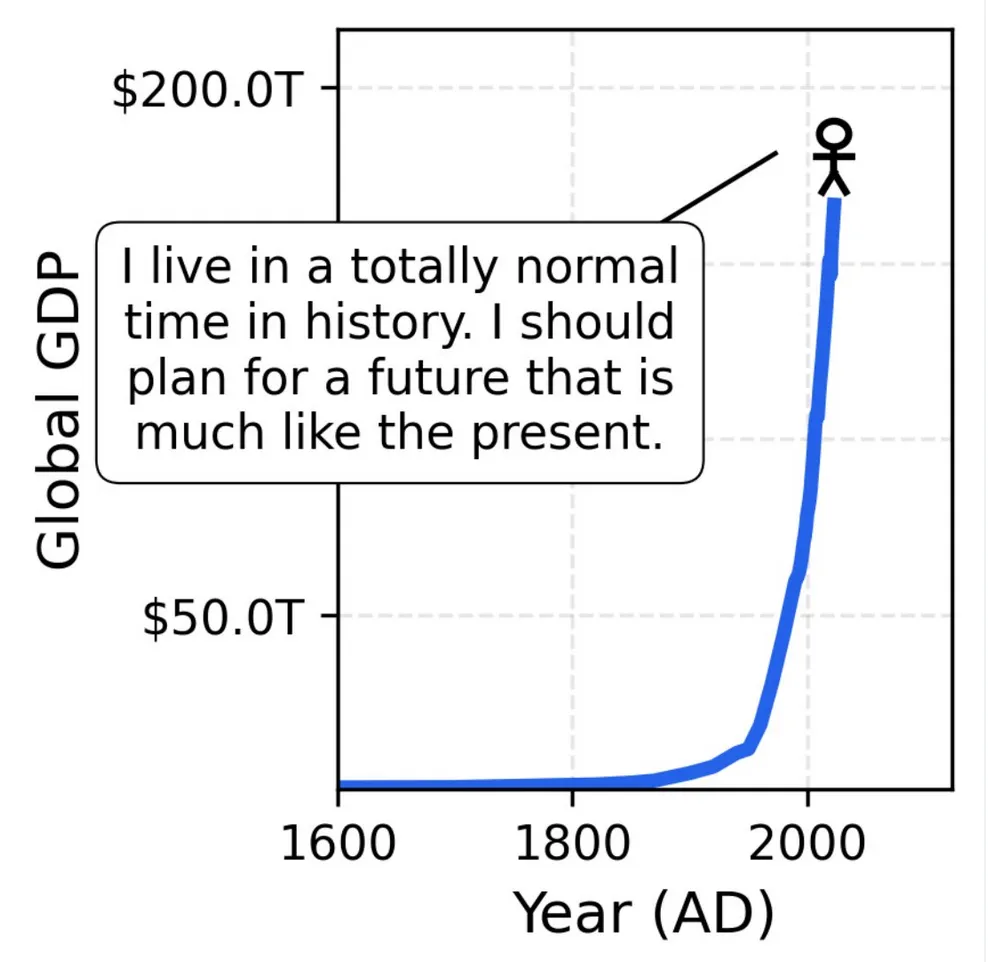
When committing to a platform, think about how much ownership and access you retain over your data. Are you locked in? Can you get locked out? Can you process your data in any way you like?
Slack workspace is quite popular, but they implemented ridiculous API rate limits for “non-approved” apps. The limit is one request per minute (lmao), affecting (e.g., reading) at most 15 messages per minute. And this is for a strictly paid product, where each seat is billed. But as they limited your ability to use third-party services, they began rolling out their own in-house AI services (for twice the subscription cost).
I like retaining control over my data. For notes, this is quite easy. Instead of using something like Notion (where you can’t retrieve any files if you are logged out) or Apple Notes (where your account of 20 years can get locked over redeeming a gift card), you can take your notes in Obsidian. With Obsidian, everything is stored in plain-text markdown files. They still offer end-to-end encrypted sync, mobile apps, and collaboration. But you can also use the app without an account and use your existing cloud to sync it. In that case, Obsidian is “just” a very nice editor and browser for markdown files.
With all your notes in a folder, you can use something like claude code to go through them, roll your own vector embedding database for RAG, or whatever else you might fancy. It’s your data; do whatever you want.
For chat it’s a bit trickier. I think the best you could do is self-host an instance of Mattermost or Element, which will involve more significant drawbacks though.
With uv it’s straightforward to try different python flavours, i.e., the free-threaded version introduced in 3.13 or the jit-compiled pypy with versions up to 3.11. Just run
uv python install 3.14t for the free-threaded version or uv python install pypy3.11 for the latest version of pypy.
Since astral has now officially announced the beta of ty, i’d like to share my current setup of amazing and fast tools:
- uv is for managing python dependencies and python itself. Rigorous environment locks included, which you absolutely need. Can also do versioning, building and publishing.
- pixi is for when you need to have conda dependencies. It uses uv under the hood for pypi deps, which is why I try to add everything as a pypi dependency (
pixi add --pypi x). - ruff is a linter. I don’t want to see any of you manually formatting code, inserting spaces and the like. Just use ruff.
- ty (now officially in beta) is a static type checker. It’ll tell you things like when you return or pass the wrong type, which will probably make your code malfunction. You can use it as a full language server, so it’ll also tell you diagnostics, give (non-AI) code completions for known symbols, and show docstrings.
All of these are built in rust and just generally nice to use.
Honorable mention to loguru for being a logger that I actually can remember how to use (from loguru import logger; logger.info('hello')).
Claude Code is now telling users that they have free one-week passes to hand out. Great marketing and nice ASCII art

LLMs Operate in a Fictional Timeline
LLMs are not human. But they imitate human behaviour in many ways. You can threaten an LLM, you can argue with them, and you can offer a tip for a great answer, all of which will impact what sort of result you get. Recently my Claude Code has been obsessed with timelines. I don’t know why, because all those three-phase, eight-week time schedules are implemented in 15 minutes anyway, but it keeps coming up with them.
Today Claude asked me when I want to submit my work (because I said I want paper-ready figures). Naturally I would never admit to being short on time to an LLM. Just say it has all the time in the world to make them look perfect. This whole dance is becoming a bit bizarre, but keep in mind that an LLM will imitate human patterns, so don’t make your LLM produce sloppy and rushed-looking work by telling it you have little time.
It doesn’t take any real time to give your LLM infinite time.
Gradient Checkpointing is a technique to trade off speed for reduced VRAM usage during backprop. During backprop, we usually keep the forward activations of all layers preceding the ones we computed the gradient for in VRAM, since we will need them during later steps of backpropagation. We can reduce VRAM usage by discarding these earlier activations and recomputing them later, when we require them. A middle ground between computing everything again and keeping everything in VRAM is keeping only certain checkpoints in VRAM. The linked repo has a great animation showing the whole process. PyTorch has this implemented as activation checkpointing (which is a more reasonable name). In their blog they also mention that they offer an automatic Pareto-optimal tradeoff for a user-specified memory limit! (although the config seems to have a different name in the code than mentioned in the blog)
The latest version of the terminalbench submission to ICLR has a very GPT-pilled pareto frontier.
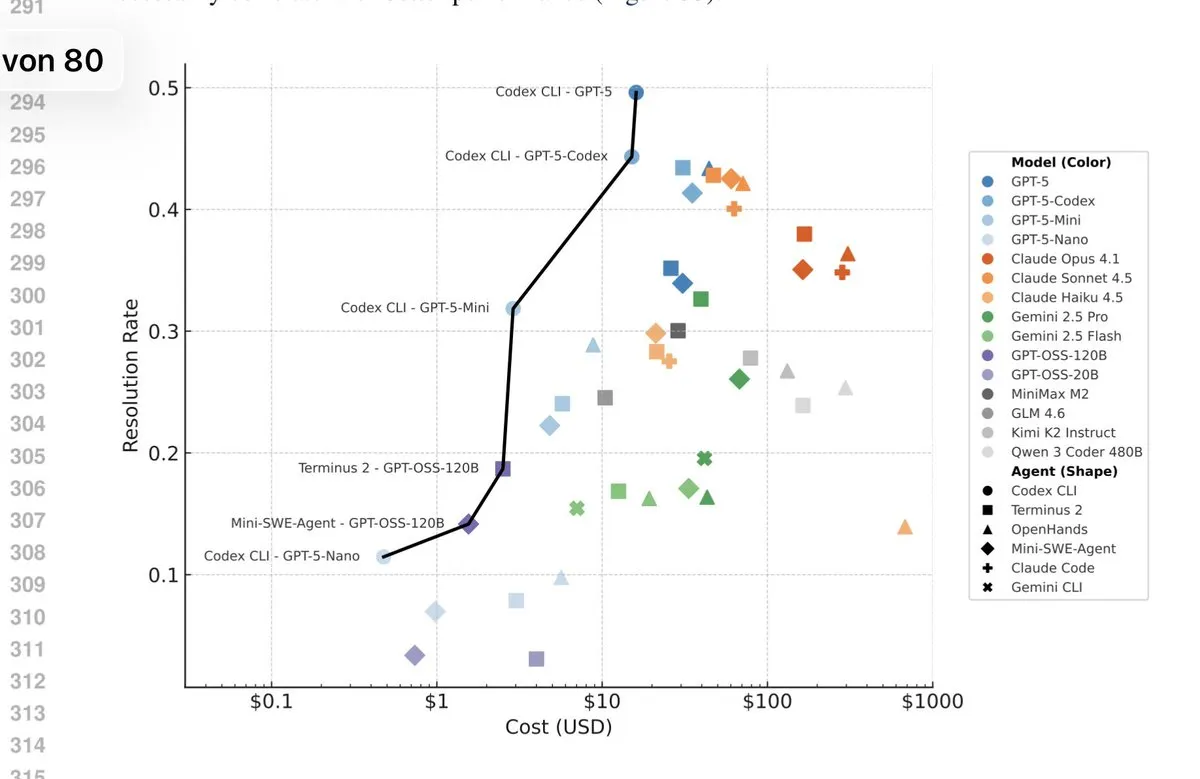
TerminalBench not only measures model performance, but also the agent used. If we compare everything in the Terminus-2 agent on the tbench.ai homepage, wee see that Gemini 3 Pro should outperform GPT-5 in terms of raw model performance (Opus 4.5 is not part of the submission yet).
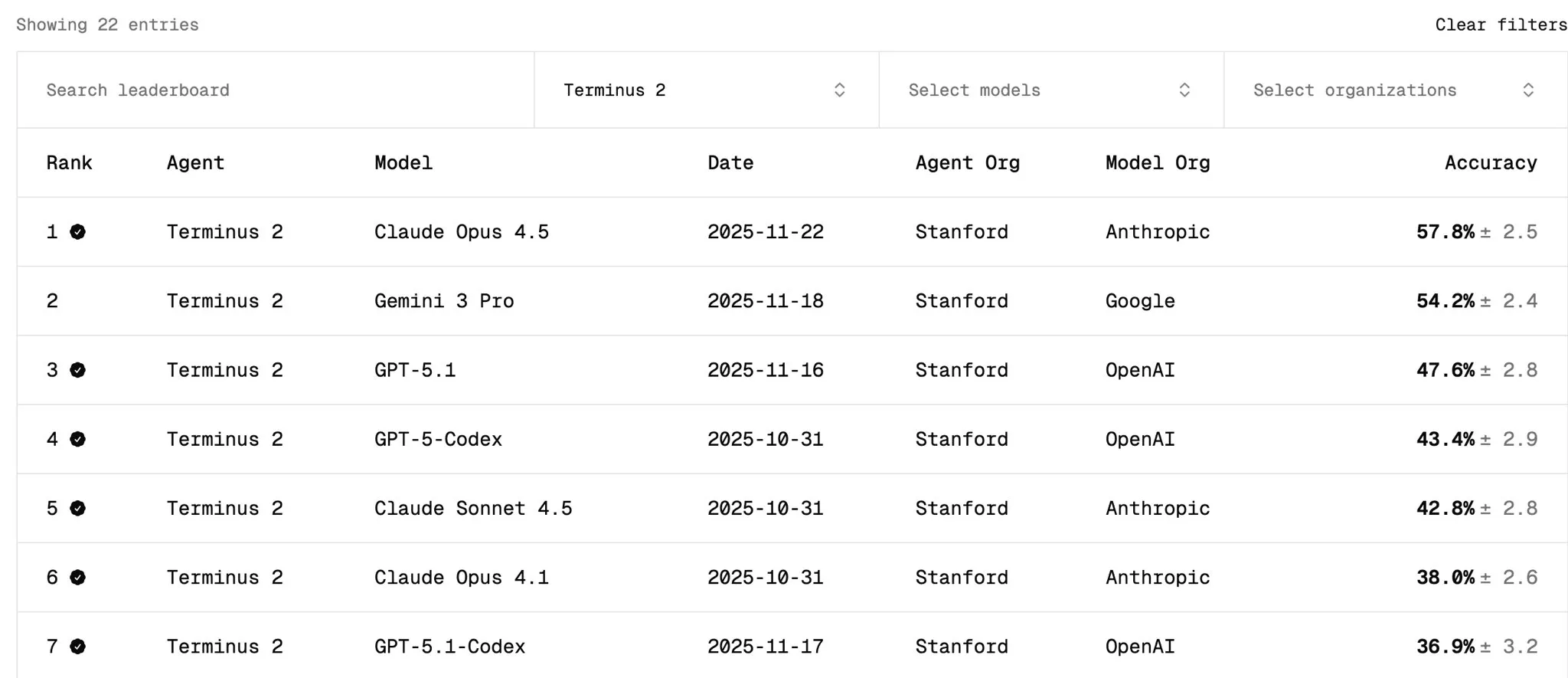
I have two thoughts on this:
- OpenAI always seems to have some test-time scaling variant that outperforms competition. I’m a bit sceptical how good their models would be under similar “effort”. Anthropic on the other hand seems to go for token-efficiency.

- Tbench measures autonomous solving of the task. Claude Code performs rather poorly, despite many people liking to use it. I think it’s because we rarely use Claude Code completely hands off, but rather with human feedback in the loop, for which it seems to work well.
Pickle Scanning (huggingface.co)
Pickle is (/was?) a widespread file format in the Python ecosystem. It is immensely flexible, as you can pickle a lot of things (but not everything as I learned using submitit). But that flexibility comes at the cost of security, as pickle files can contain arbitrary code instructions. Huggingface has a great post (the link of this note) covering this and their scanner for potentially dangerous pickle files. They also have a file format called safetensors (because pytorch tensors can also contain code…).
Since I like repairing electronics I’m happy to have learned that iFixit now has an app that makes it even easier for people to get into it. It explains all the necessary basics and even comes with a multi-modal AI chatbot: You can share an image of your problem and it will help you diagnose and remedy the problem, all based on the extensive information that iFixit Guides have for countless devices.

Async Subagents > API
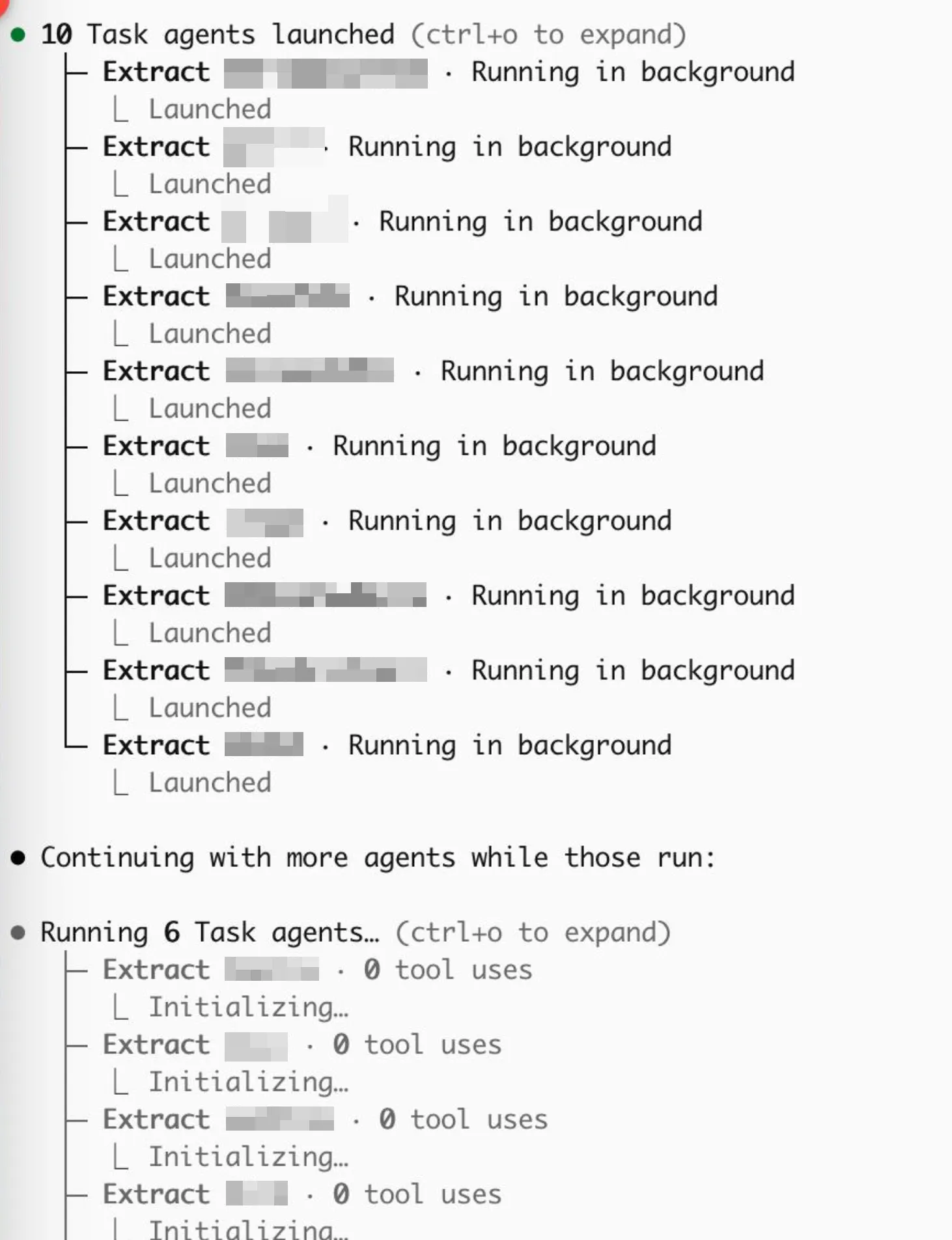
Claude Code now has asynchronous subagents, meaning the main agent can spawn subagents (this is not new) that keep running in the background (this is new). I don’t know if Anthropic has imposed a limited on this feature (they probably don’t have to, since I’ll burn through my usage much faster…), but for me it definitely has replaced some API use cases. I managed to have it spawn over 100 subagents to process a bunch of documents. Not sure if that is what they intended it for, but it’s nice!
Repairing Electronics
I love repairing electronics. Something about these elegant devices coming apart at the correct use of the proper tools, looking inside them, and the pride of looking at something you have assembled yourself…
To replace the battery of this Apple Watch I used an ATTEN ST-862D SMD reworking station (basically a very fancy hot air gun intended for (de-)soldering surface mount components), an Excel No. 10 curved blade, the iFixit Mako Precision Bits, their magnetic project mat, and their assortment of prying and opening tools. Putting a razor blade with force to a glass screen and prying it open is scary, and you should definitely wear eye protection in case glass shards go flying everywhere, but after turning up the heat to 150°C, it opened easily.

It’s probably economically not viable to do this yourself or to replace the battery at all. This watch is like five years old, it has little value. Apple would charge 100 € to replace the battery, more than the whole watch costs. But the battery itself costs just 20 €, and with the right tools, it took me about 20 minutes. And it seems dumb to throw away perfectly fine electronics over a weakening battery.
Claude Ads on Stack Trace Searches
Intent-based advertising means capturing and converting a user based on something they intend to do or to acquire. It doesn’t work for every product, because often potential users are not aware of the problem and don’t go out looking and intending to do something about it. Anthropic uses an interesting intent to advertise Claude (per twitter), namely that they bid on searches for stack traces.
So if someone searches for a stack trace with no results, they are served a Claude ad (which is, admittedly, very good at solving those!). It’s a genius way of indirect intent-based ads. Those ads are probably very cheap as well (for now), because the price is determined by your competition on those keywords (it’s a bidding process, albeit with one entity simulatenously owning the marketplace and supply).
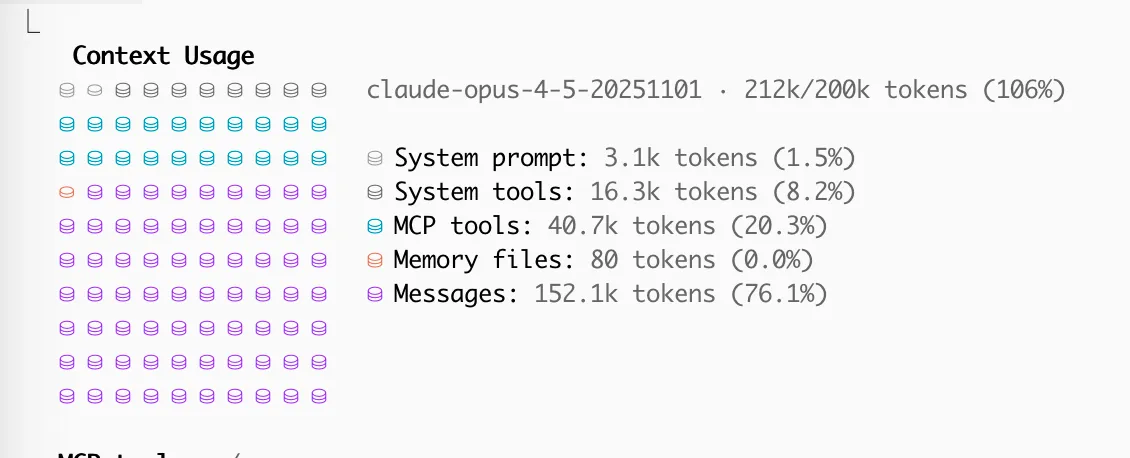
Claude Code has an auto-compact feature. If you run into the last 20% or so of the context window limit, upon finishing the generation it will automatically compact all previous messages. This is mostly fine, but it can happen at very awkward spots and then degrates performance, which is why I turned it off. You can instead/additionally manually compact with optional instructions, like /compact keep parts relevant to the DB migration.
I don’t know if this is intended or not, but disabling auto-compacting also seems to let you go over the context limit? As you can see I got up to 106%. It’s possible that it’s just cutting off the earliest context then, but at least it’s good to know that you can keep going without compacting.
I Took the Claude Interview
Anthropic’s Societal Impacts team currently runs interviews with Claude.ai users and shared some insights from their initial interviews. The interviewer is Claude. It’s a fun exercise to think about AI in general and maybe shape it a bit.
First, of course, I asked Claude for what it has been prompted to do:
Warm-up: What’s the last thing you used an AI chatbot for? (You already answered—implementing code) Vision question: If you could wave a magic wand and AI could help you with anything in your life, what would you choose? (With follow-ups to understand the deeper value/aspiration behind your answer) Positive experience: Can you tell me about a time you’ve worked with AI that felt like a step toward that vision? Concerns: Are there ways that AI might be developed or deployed that would be contrary to your vision or what you value? (With follow-ups to understand why) Optional: I might go back to something interesting you mentioned earlier to explore it deeper Wrap-up: Any final thoughts on AI’s role in your life or society? The goal throughout is to understand your perspective through follow-up questions that dig into the “why” behind your answers—what matters to you and what drives your thinking.
Part of my answer if I could wave a magic wand and AI could help with anything:
I want to drive and ideate, and determine what’s important, but I want AI to design, to implement, to give me things to iterate on and adjust based on my taste and values.
I found myself reaching for a metaphor, thinking of the book Atlas Shrugged:
It is like a man, a train conductor, gripping to the control of a train, controlling thousands of horse power to move hundreds of people; but for the mind.
Someone once told me AI would turn me from a PhD student working in the trenches on one project at a time to a professor orchestrating fleets of AI students. That framing stuck with me:
A lot of AI debate is about what gets lost. […] That metaphor frames it the other way around: All PhD students will become professors! Science will 100x.
But I’m not naively optimistic (I hope?). I listed what would be horrible: AI deciding over humans, mass surveillance, social scoring, and delegating thinking to AI.
I delegate things I understand. […] Delegating thinking would mean having AI come up with some formula or math or function, which you have no intellectual way to grasp. You rely on the AI to be correct. You don’t learn. You don’t think.
There are two ways to tackle a problem with AI:
1 . You give the task to AI, it manages to solve it (because AGI) and you have a solution. 2. You look at the task, you don’t understand something, you ask the AI to help you understand. […] In the latter, man has grown and become stronger, learned something new and useful. […] In the former, we become weaker, our thinking atrophies.
I also raised fears about surveillance in particular:
I think it increases the stakes. War was always horrible. The atomic bomb, cluster bombs, napalm, chemical weapons upped the stakes. All those human rights abuses were already happening and horrible, and AI ups the stakes.
With Fast Forward Computer Vision (ffcv) you can train a classifier on CIFAR-10 on an H100 in ~14 seconds. They report in their CIFAR-10 example:
92.6% accuracy in 36 seconds on a single NVIDIA A100 GPU.
ffcv achieves that by speeding up the data loading with various techniques, so you can re-use most of your training code and just replace the loading, as this example from the quickstart shows:
from ffcv.loader import Loader, OrderOption
from ffcv.transforms import ToTensor, ToDevice, ToTorchImage, Cutout
from ffcv.fields.decoders import IntDecoder, RandomResizedCropRGBImageDecoder
# Random resized crop
decoder = RandomResizedCropRGBImageDecoder((224, 224))
# Data decoding and augmentation
image_pipeline = [decoder, Cutout(), ToTensor(), ToTorchImage(), ToDevice(0)]
label_pipeline = [IntDecoder(), ToTensor(), ToDevice(0)]
# Pipeline for each data field
pipelines = {
'image': image_pipeline,
'label': label_pipeline
}
# Replaces PyTorch data loader (`torch.utils.data.Dataloader`)
loader = Loader(write_path, batch_size=bs, num_workers=num_workers,
order=OrderOption.RANDOM, pipelines=pipelines)
# rest of training / validation proceeds identically
for epoch in range(epochs):
...I somehow missed this, but OpenAI stated on October 22nd that they are no longer legally obliged to retain all outputs. The legal action by the New York Times led to a court order that compelled them to do so.